
Ormai tutto in Italia sembra proiettato verso la fatidica “Fase 2” dell’epidemia da Sar-Cov-2: la fase in cui, terminata finalmente l’emergenza, inizierà un periodo di convivenza col virus e la graduale ripresa delle attività economiche e della vita sociale. Ma questa Fase 2 sta davvero arrivando? E quando esattamente arriverà? Come sempre ci affidiamo ai dati empirici per cercare di trovare una risposta.
È essenziale, infatti, in questa fase non commettere errori. Se da un lato non riaprire le attività (soprattutto il motore economico del Paese) rischia di farci rimanere indietro e di avviare un periodo di recessione ancora più grave, dall’altra riaprire le attività troppo presto rischia di gettarci nuovamente in situazioni emergenziali le quali possono mettere a serio rischio il sistema sanitario oltre che la vita di molti connazionali. Del resto, nel medio periodo, questo secondo errore avrebbe peraltro una ricaduta negativa anche sull’economia. Su questo aspetto, il premio Nobel Paul Krugman ha recentemente messo in guardia le nostre economie relativamente al rischio di una riapertura prematura del sistema ricordando come, nel corso dell’epidemia della influenza cosiddetta “Spagnola” del 1918-20, le regioni che mantennero più a lungo le misure restrittive non solo limitarono il numero di morti, ma nel medio periodo riuscirono ad ottenere anche migliori performance dal punto di vista della ripresa economica.
Ecco dunque che appare cruciale poter disporre di modelli affidabili di previsione della data nella quale il numero di contagi approssimerà finalmente lo zero e quando possiamo immaginare un graduale ritorno alla normalità.
Un modello statistico, tuttavia, è come una pietanza. Perché sia buona occorrono buoni ingredienti e una buona ricetta, oltre che, ovviamente, le capacità del cuoco. Gli ingredienti sono rappresentati dai dati di base; il bravo cuoco li sceglie accuratamente sapendo che da essi dipenderà in maniera fondamentale la qualità del risultato. Il cuoco improvvisato, invece, apre la dispensa e vede solo cosa c’è a disposizione. I modelli corrispondono, invece, alle ricette da seguire e, proprio come in una ricetta, si traducono in passi da compiere, operazioni da eseguire sui dati secondo un predeterminato schema ordinato e una sequenza temporale i quali, sulla base di teorie, di precedenti esperienze e di risultati sperimentali, ne garantiscono il rigore e quindi un’elevata probabilità di ottenere un buon prodotto finale.
Gli ingredienti
Va subito detto con chiarezza che, al momento in cui scrivo, nessun modello statistico è in grado di prevedere in modo affidabile il giorno (o comunque un intervallo di tempo così ristretto da essere operativamente utile) in cui il numero di infetti in Italia scenderà a zero. E questo per una semplicissima constatazione: non sappiamo neanche quale sia il numero esatto degli infetti in Italia in questo preciso momento!
Gli ingredienti che abbiamo a disposizione per cucinare sono di scarsa qualità ai fini di previsioni. I dati pubblicati giornalmente dalla Protezione civile, infatti, com’è ben noto a tutti, riguardano prevalentemente gli infetti acclarati, ovvero i pazienti ai quali è stato somministrato il tampone. Il numero reale di contagiati resta invece sottostimato, in quanto, salvo rare eccezioni, non è stato possibile finora identificare i pauci-sintomatici e gli asintomatici.
Molti hanno provato ad azzardare ipotesi a tale riguardo. La virologa Ilaria Capua in un’intervista rilasciata il 25 febbraio (la data di ognuna delle congetture in questo contesto è importante) ipotizzava che solo un terzo degli infetti manifestasse sintomi, mentre il capo del Dipartimento della Protezione Civile, Angelo Borrelli, il 6 di aprile, basandosi su studi relativi alla regione di Hubei, affermava che gli infetti potrebbero essere fino a 10 volte il numero di quelli rilevati. Il tasso di asinotomatici si collocherebbe, invece, tra il 50% e il 75% secondo gli esami svolti a Vo’ Euganeo. A livello internazionale, un gruppo di ricerca misto nippo-statunitense in un lavoro del 12 marzo basato sull’osservazione dei passeggeri della nave da crociera Diamond Princess, stimava che gli asintomatici rappresentassero circa il 18% degli infetti. Sempre in Giappone, un gruppo di ricerca delle università di Sapporo e di Osaka affermava, invece, a metà febbraio, che tale tasso sarebbe del 25%, un dato che troverebbe anche conferma nello studio del “Centers for Disease Control and Prevention” di New York, riportato dal New York Times il 31 di marzo.
Il 22 marzo il governo cinese confermava l’ipotesi-Capua con un tasso di asintomaticità stimato al 33%, ma tale tasso salirebbe, invece, all’80% secondo l’Oms nel suo rapporto del 6 marzo, mentre sarebbe del 60% secondo il World Economic Forum. La prestigiosa rivista Science, infine, al 16 marzo stimava che l’86% degli infetti non manifesta problemi evidenti di salute pur essendo in grado di trasmettere la malattia al 79% dei malati accertati.
Il lettore mi perdonerà questo bombardamento di cifre e di link al web, ma certamente concorderà con me che tutte queste stime così discordanti ci portino a un’unica conclusione: a oggi non abbiamo contezza della percentuale degli asintomatici e dei pauci-sintomatici e quindi del numero di infetti attualmente presenti sul suolo nazionale. La tabella seguente mostra le diverse stime del numero degli infetti in Italia implicate dalle varie ipotesi che abbiamo qui brevemente passato in rassegna.
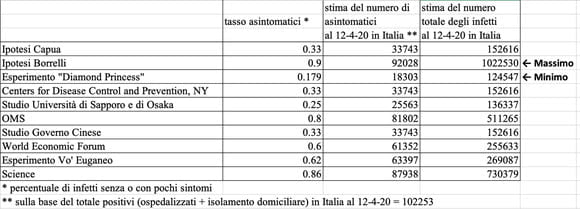
Come si vede il numero di infetti in Italia a oggi potrebbe variare tra circa 120.000 e 1.000.000 a seconda delle diverse ipotesi! Un margine assolutamente troppo ampio per potervi affidare qualunque decisione avente a cuore la salute pubblica.
Come ho già osservato in un mio precedente contributo su ilsussidiario.net, l’inadeguatezza dei dati ufficiali in nostro possesso (non solo in Italia) risiede nel fatto che essi sono stati fin qui raccolti non con finalità statistiche, ma solo emergenziali e quindi non costituiscono un campione statistico attraverso il quale si possa generalizzare i risultati a tutta la popolazione.
L’evidente sottostima degli infetti nel nostro Paese non sembra aver vanificato gli sforzi dei modelli nel prevedere sia il picco epidemico, che è stato correttamente previsto dalla maggior parte dei modelli, sia il picco dei casi (che sta per essere raggiunto secondo gli stessi modelli). La detta sottostima, tuttavia, non rende possibile una previsione sufficientemente accurata del momento di “zero contagio” e di altri parametri di cruciale importanza nel momento in cui si devono prendere decisioni circa l’allentamento delle misure di contenimento.
È ormai opinione diffusa in ambito scientifico che sia necessario avviare un’indagine campionaria basata su un preciso disegno statistico che abbia lo scopo di fare chiarezza su tale aspetto prima di prendere decisioni che potrebbero rivelarsi catastrofiche per le conseguenze sia sulla salute pubblica che sull’economia. Tale necessità è stata sottolineata con forza da studiosi della Società Italiana di Statistica (vedi anche qui), ma anche da immunologhi, epidemiologi, virologi e microbiologi (vedi anche qui).
Senza una base-dati affidabile, qualsiasi tentativo di prevedere la futura evoluzione della pandemia sarebbe, infatti, destinato a fallire. In tal senso è di pochi giorni fa la notizia della costituzione presso l’Istituto Nazionale di Statistica, in accordo con la Società Italiana di Statistica, di un Advisory Committee avente il compito di progettare rilevazioni ufficiali finalizzate ad acquisire elementi conoscitivi collegati all’emergenza sanitaria in corso. È poi del 10 aprile l’annuncio di una ricerca da parte della task force istituita per la Fase 2 basata su un campione casuale stratificato di almeno 150.000 persone la quale potrebbe fare finalmente chiarezza su questo aspetto di qualità del dato dell’informazione.
Tali indagini saranno di importanza fondamentale per migliorare la qualità degli ingredienti a disposizione dei modellisti. Esse dovranno avere due caratteristiche: dovranno essere ripetute nel tempo per seguire l’evoluzione dell’epidemia e dovranno riguardare anche test sierologici per verificare la presenza di anticorpi. Non occorrono campioni troppo ampi e dispendiosi per giungere ad una buona significatività dei risultati. Solo campioni ben fatti.
La situazione di carenza informativa attuale non riguarda, per la verità, solo il nostro Paese. Poche sono, in effetti, le eccezioni di iniziative volte a una quantificazione corretta dell’entità del fenomeno epidemico. Al momento in cui scrivo ho notizia solo di indagini che sono state condotte (o programmate) solo in Australia, in Romania e in Germania.
Le ricette
Abbiamo argomentato fin qui la necessità di fondare previsioni statistiche dell’evoluzione dell’epidemia su basi di dati affidabili. “Senza dati siete come ciechi e sordi nel bel mezzo di un’autostrada”, affermava il consulente manageriale americano Geoffrey Moore nel 2014. Tuttavia, possiamo avere a disposizione anche una vasta mole di dati di qualità, ma senza un modello adeguato, in quell’autostrada, pur vedendoci e sentendoci benissimo, rischiamo comunque di perire investiti.
I modelli non sono evidentemente tutti uguali. Ne esistono di buoni e di meno buoni e ve ne sono anche di completamente errati come vediamo, purtroppo, anche in questi giorni.
Quello che chiamiamo modello statistico rappresenta una semplificazione della realtà, congegnata per evidenziare alcune caratteristiche essenziali dei fenomeni osservati tralasciandone altre giudicate trascurabili per la loro comprensione. Invero, tutta la scienza è spesso identificata proprio come il luogo della ricerca di teorie in grado di spiegare in maniera semplice, ma sufficientemente adeguata la complessità osservata empiricamente. I fenomeni empirici sono complessi per loro natura e non possiamo ambire di riuscire a fornirne una spiegazione esaustiva in tutti i suoi molteplici aspetti. L’importante missione affidata al metodo statistico è, dunque, quella di fornire una loro rappresentazione approssimata, e di ricercare meccanismi che ne descrivano la natura in modo magari imperfetto, ma comunque operativamente utile.
Un modello previsivo buono è uno che tiene conto della qualità del dato in entrata e della specificità del fenomeno analizzato. Uno modello meno buono è quello che trascura la qualità del dato utilizzato e che interpola meccanicamente gli andamenti temporali del fenomeno senza tener conto della sua specificità. Questa seconda specie di modelli può anche dare frutti discreti a fenomeno in corso (ad esempio dopo il passaggio del picco epidemico), ma raramente riesce a prevederne accuratamente i punti di svolta.
Un esempio di modello errato nei suoi fondamenti è rappresentato dall’uso (visto in questi giorni) di uno pseudo-indicatore dell’uscita dalla crisi epidemica basato sull’incremento percentuale dei nuovi casi (ovvero il rapporto tra i nuovi casi giornalieri e il totale dei casi). Il fatto che questa percentuale cali nel tempo non è un segnale positivo per l’epidemia (come taluni interpretano), ma solo una caratteristica della misura stessa. Essa tende, infatti, sempre a zero per definizione anche in fasi di crescita esponenziale della diffusione del virus.
Esempi di questo genere sono, ahimè, molto diffusi in questi giorni. Anche se gli ingredienti sono ottimi, le ricette possono essere sbagliate e, in mano a cuochi improvvisati, possono condurre a pietanze immangiabili.
Non si può però condividere il pensiero di Gilberto Corbellini espresso nell’articolo intitolato: “Se mentono pure i numeri” apparso il 7 aprile sul Sole 24 Ore. In esso si legge: “È il loro momento. Mai prima, di fronte a un fenomeno complesso e mondialmente impanicante come la pandemia, statistici, modellisti e matematici hanno goduto di tanto ascolto e fama. I modelli matematici di fenomeni complessi sono affascinanti, forse eccitanti. Ma sono anche epistemologicamente ingannevoli. I modellisti si sono dimenticati la raccomandazione dello statistico britannico George Box: «Tutti i modelli sono falsi. Ma qualcuno è utile».
Non credo valga la pena scomodare il pensiero epistemologico post-positivista per ricordare ai detrattori dei modelli statistici che per uno scienziato non conta tanto affermare una verità assoluta, ma solo approssimare meglio di chiunque altro le spiegazioni ai fenomeni empiricamente osservati. D’altra parte, il principio di indeterminazione di Heisenberg, sottolinea il carattere probabilistico persino della fisica, sostituendo all’idea di una fisica deterministica, un approccio basato su leggi statistiche che sono valide sì solamente fino a prova contraria, ma sono comunque operativamente rilevanti per prendere decisioni. La frase di George Box va esattamente intesa in questo senso.
Dei modelli previsivi continueremo ad averne bisogno per uscire da questa crisi con buona pace di chi li critica a priori. A cosa altro possiamo affidarci per prendere decisioni empiricamente fondate? Basta che i modelli siano ben cucinati, con ingredienti buoni e ricette non improvvisate.